Submitted to NeurIPS 2026
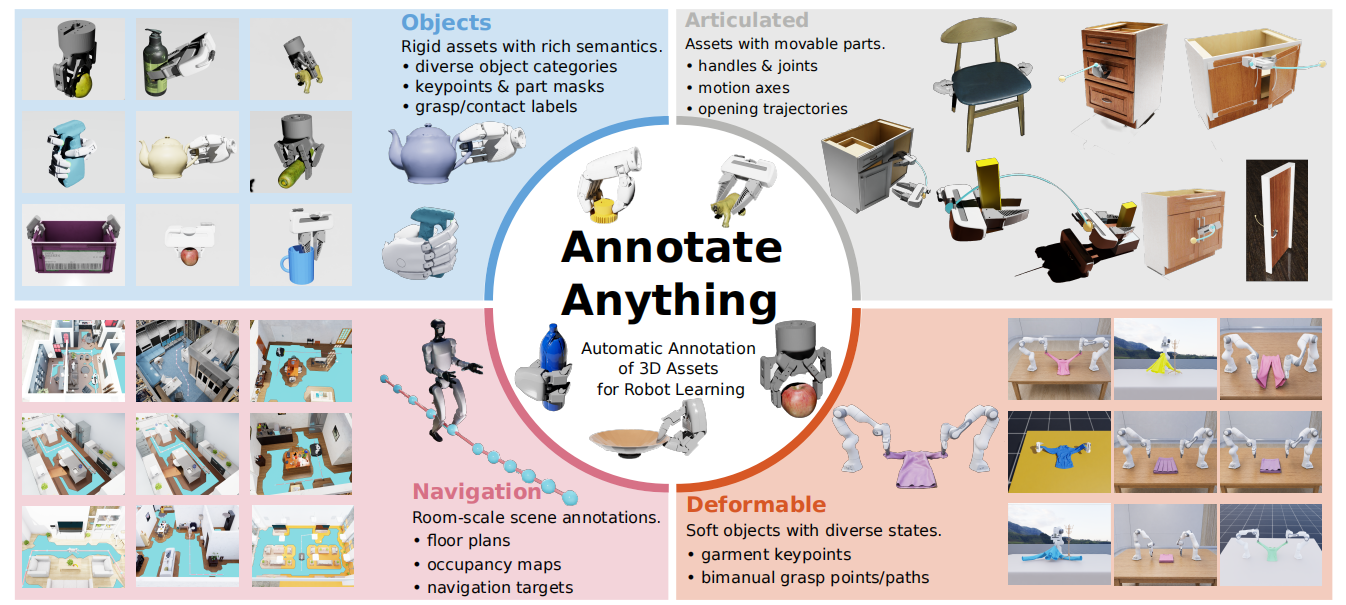
Simulation enables scalable robot data collection, but raw 3D assets usually provide only geometry and appearance. AnnotateAnything is an automatic annotation framework that turns object- and room-scale 3D assets into manipulation-ready assets with structured language, visual, and action annotations. A visual-language annotation pipeline infers semantics, parts, keypoints, occupancy maps, and interaction priors, while a physics-based action annotation pipeline converts these priors into executable labels such as grasp poses, dexterous contacts, articulation waypoints, insertion directions, hanging affordances, garment trajectories, and navigation targets. The resulting annotations can be consumed by reusable atomic skills for large-scale simulation data collection and downstream robot learning tasks.
AnnotateAnything is organized around a visual-language-action annotation pipeline.
Generate multi-level object and room descriptions, semantic keypoints, part masks, occupancy maps, and floor-plan cues.
Ground visual-language priors into executable action candidates through target generation, optimization, validation, and augmentation.
Use reusable atomic skills to consume grasp, dexterous grasp, articulation, garment, hanging, insertion, and navigation labels.

Representative annotation-enabled rollouts across articulated objects, dexterous and parallel grippers, and bimanual skills.




| Level | Annotation | Example outputs |
|---|---|---|
| Asset | Language | Sparse tags; object-, part-, and task-level descriptions |
| Asset | Visual | 3D keypoints; part masks; geometric regions |
| Room | Language | Scene descriptions; object relations; task contexts |
| Room | Visual | Occupancy maps; floor plans; top-view layouts |
| Action | Manipulation | Grasps; dexterous contacts; articulation waypoints; insertion and hanging poses |
| Action | Scene | Navigation targets; approach poses; interaction-ready base poses |
Detailed quantitative tables will be added after the anonymous submission is finalized.
@inproceedings{anonymous2026annotateanything,
title = {AnnotateAnything: Automatic Annotation of 3D Assets for Robot Manipulation},
author = {Anonymous Authors},
booktitle = {Submitted to NeurIPS},
year = {2026}
}